
Анализ данных об использовании социальных сетей
Введение
В рамках проекта я проанализировал базу данных, содержащую информацию о времени, которое пользователи проводят в социальных сетях. Данные были найдены на платформе Kaggle.
Исследование посвящено выявлению закономерностей в использовании соцсетей в зависимости от возраста, интересов, уровня дохода, пола и других факторов. Анализ может быть полезен для маркетологов, разработчиков digital-продуктов и всех, кто интересуется цифровыми привычками пользователей.
Для визуализации использованы цвета из палитры tab20b библиотеки matplotlib, что позволило добиться визуальной целостности и читаемости инфографики.

Этапы работы
Для работы с данными были подключены библиотеки: Pandas и NumPy — для анализа, Matplotlib и Seaborn — для визуализации, Scikit-learn и SciPy — для построения модели и работы с выбросами.

Данные были загружены с компьютера и прочитаны с помощью pandas. Для первичного анализа были выведены первые строки, типы данных и базовая статистика.
Замена пропусков
Затем я проверил наличие пропущенных значений в таблице. Я заполнил пропуски следующим образом: В числовых столбцах — средним значением по соответствующей колонке. В категориальных столбцах — наиболее часто встречающимся значением (модой). Таким образом, удалось избежать искажений, связанных с отсутствующими данными, и сохранить как можно больше информации для анализа.
Фильтрация и сортировка
На этом этапе я применил фильтрацию по возрасту: отобрал пользователей старше 50 лет и отсортировал их по доходу. Boxplot (ящик с усами) показал, что их доходы распределены равномерно, медиана — около 14–15 тыс., выбросов не наблюдается.
Ящик с усами
Далее была выполнена фильтрация по нескольким условиям: я выделил женщин с доходом выше среднего и отсортировал их по времени в соцсетях. Диаграмма рассеяния показала, что прямой зависимости между доходом и временем в соцсетях нет — поведение остаётся индивидуальным и разнообразным.
Диаграмма рассеяния
Новые признаки
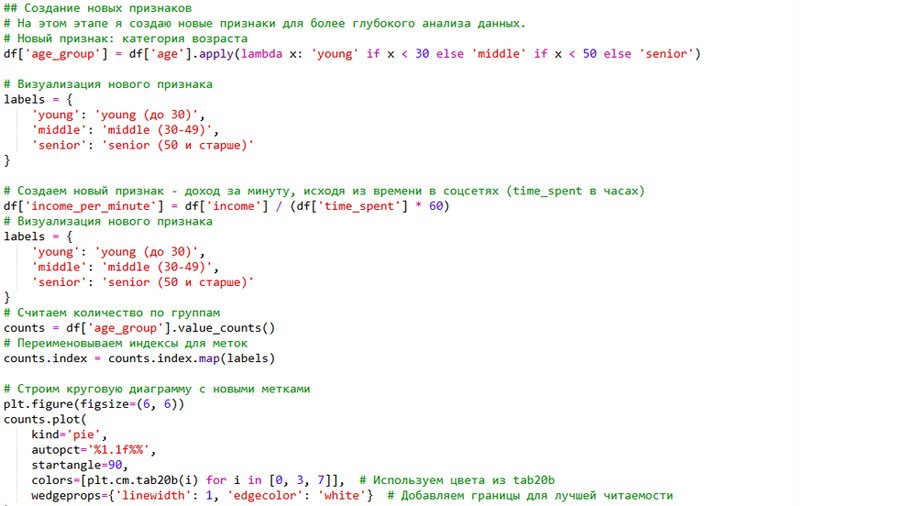
На этом этапе я создал два новых признака: Первый — возрастные группы (критерий: создание признака через анонимную функцию), что позволило наглядно показать, что большинство пользователей — от 30 до 49 лет.
Круговая диаграмма
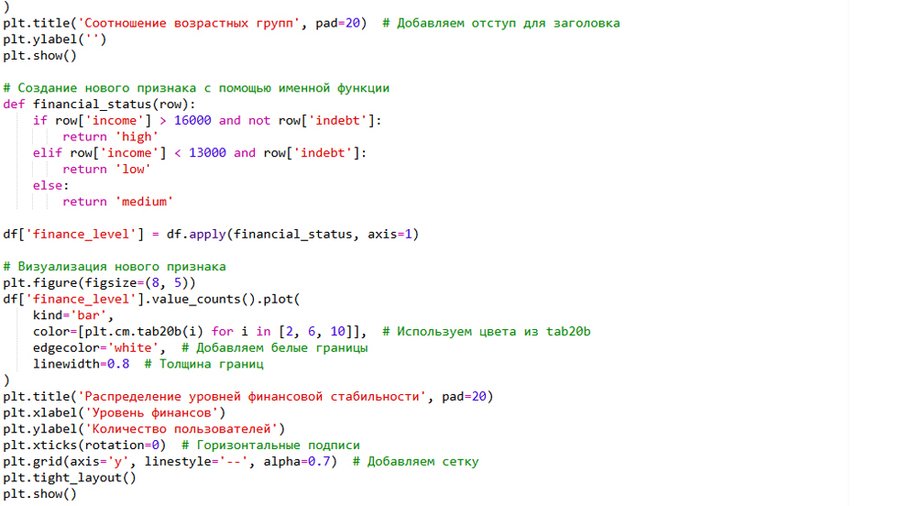
Второй признак — уровень финансовой стабильности, сформированный через именную функцию (критерий: создание признака с помощью именной функции). На графике видно, что большинство пользователей относятся к средней группе по финансовым параметрам.
Гистограмма
Сводные таблицы
В этом блоке я построил 5 сводных таблиц и визуализировал их в виде столбчатых диаграмм (bar chart), используя разные комбинации признаков, методов и группировок.
Столбчатая диаграмма
Я построил первую сводную таблицу (критерий: группировка по одному признаку — age_group). График показывает, что наивысший средний доход — у пользователей группы middle (30–49 лет), примерно 15,500. У групп senior и young доход ниже. Это соответствует рыночным ожиданиям и возрастной траектории роста доходов.
Составная столбчатая диаграмма
Создана сводная таблица по двум признакам (age_group и gender) — критерий: группировка по нескольким признакам.
График демонстрирует, что в группах middle и senior женщины зарабатывают больше мужчин. Это нетипичный результат, который может указывать на особенность датасета. В группе young разница между полами минимальна.
Составная столбчатая диаграмма
На основе среднего значения по двум числовым показателям (age, time_spent) построена таблица — критерий: агрегация двух переменных. Время в соцсетях стабильно во всех группах (примерно 5 часов), но молодёжь проводит в соцсетях не сильно больше, чем старшие категории, что может указывать на переосмысление цифровых привычек.
Составная столбчатая диаграмма
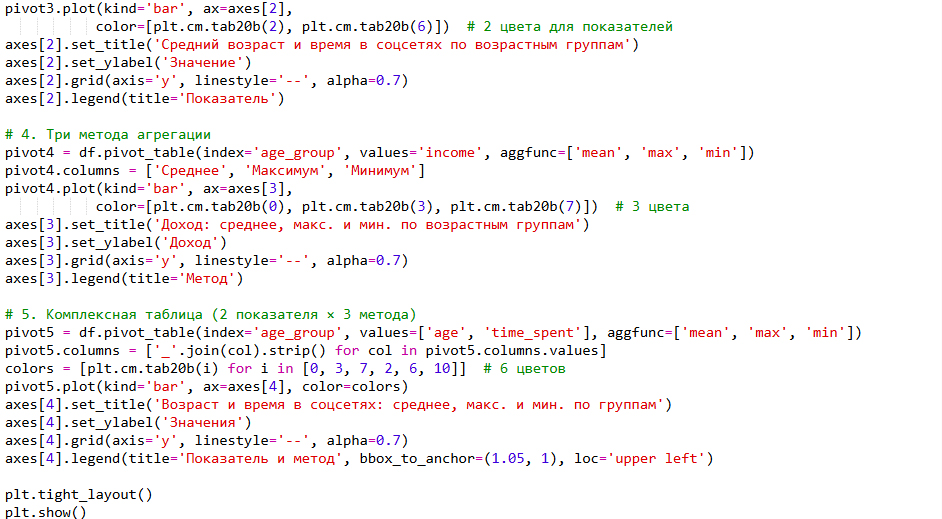
Здесь реализовано сравнение трёх методов агрегации (mean, max, min) — критерий: множественная агрегация по одному признаку. Во всех группах максимальный доход близок к 20,000. У middle наблюдается наивысшее среднее значение и умеренный разброс. Это говорит о том, что в этом возрасте зарабатывают как низкооплачиваемые специалисты, так и высокооплачиваемые профессионалы.
Составная столбчатая диаграмма
Комплексный анализ двух признаков (age, time_spent) с тремя методами агрегации — критерий: множественная агрегация по нескольким числовым столбцам.
Максимальное время в соцсетях стабильно и одинаково у всех — примерно 9 часов. Средние значения возраста и минимальные значения времени показывают ожидаемые возрастные различия, но не подтверждают гипотезу о том, что молодёжь — самые активные пользователи.
Удаление выбросов
На этом этапе я удалил выбросы из данных с помощью двух методов.
Гистограмма
Гистограмма
Первый — метод трёх стандартных отклонений, применённый к целевой переменной time_spent (критерий: метод N стандартных отклонений для целевого признака). Я построил две гистограммы — до и после удаления выбросов. Они полностью совпадают. Это объясняется тем, что распределение значений изначально было равномерным, а выбросов оказалось крайне мало — настолько, что удаление не повлияло на визуальную форму графика вообще.
Ящик с усами
Ящик с усами
Второй — метод 1.5 IQR, применённый к количественному предиктору income. Я построил боксплоты до и после удаления выбросов. Графики оказались абсолютно идентичными: медиана, границы коробки и усы остались неизменны. Это свидетельствует о том, что исходные данные были устойчивыми, и выбросы имели крайне малое влияние.
Таким образом, оба метода были реализованы, данные успешно очищены, но визуальная структура распределений осталась полностью неизменной — это подтверждает хорошее качество выборки.


После удаления выбросов (time_spent — по 3σ, income — по 1.5 IQR), я получил датафрейм df_clean2.
Пропусков нет, 1000 строк — объём не пострадал. Типы данных корректны, все признаки сохранены. Средний доход — 15 015, медиана — 14 904 — распределение симметричное. Среднее время в соцсетях — 5 минут в день. Новые признаки income_per_minute и finance_level тоже очищены. Дальнейший анализ — только на df_clean2.



Описательные статистики
На этом этапе я исследовал целевой количественный признак — доход (income).
Первый шаг — меры центральной тенденции (критерий: расчёт и визуализация среднего и медианы). Медиана показывает значение дохода, которое делит выборку на две равные части — 50% пользователей имеют доход ниже 14904, 50% — выше. Среднее значение дохода — 15 015. Медиана — 14 904, чуть ниже. Это говорит о слабой асимметрии в сторону более низких значений: у большинства пользователей доход ниже среднего.
Гистограмма с линиями среднего и медианы
Второй шаг — квартильный анализ (критерий: расчёт и визуализация всех квартилей). Распределение дохода показано через деление на 4 части — квартели. 25% пользователей зарабатывают менее 12 402, 75% — менее 17 674. Все значения после удаления выбросов укладываются в границы «усов».
Ящик с усами
Третий и четвёртый шаги — разброс и категориальный признак (критерии: расчёт мер разброса и описание категориального признака)
Доходы пользователей варьируются в пределах 9 968 (размах). IQR — 5 272 показывает ширину основной «средней» группы. Стандартное отклонение — 2 959, то есть большинство доходов отклоняются от среднего примерно на эту величину.
Категориальный признак gender описан без графика, так как данные легко читаются в числах: мода — male, это самая частая категория. Всего три уникальных значения: female, male, non-binary.
Корреляция Пирсона
Корреляционный анализ (критерий: визуализация матрицы и интерпретация самой сильной корреляции) Я построил тепловую карту, чтобы проанализировать связи между количественными признаками. Самая сильная корреляция оказалась между time_spent и income_per_minute (—0.80): чем больше человек проводит времени в соцсетях, тем меньше его доход за минуту. Это логично: высокая эффективность времени часто означает меньше времени онлайн. Диаграмма рассеяния помогает визуально подтвердить: чем больше time_spent, тем ниже income_per_minute.
Тепловая карта (корреляционная матрица)
Диаграмма рассеяния (между двумя самыми скоррелированными признаками)
Линейная регрессия
Цель этого этапа — построить парную линейную регрессию и проверить, влияет ли количество времени, проведённого в соцсетях (time_spent), на доход в минуту (income_per_minute).
Диаграмма рассеяния + линия регрессии
Общее уравнение: income_per_minute = β₀ + β₁ * time_spent + ε
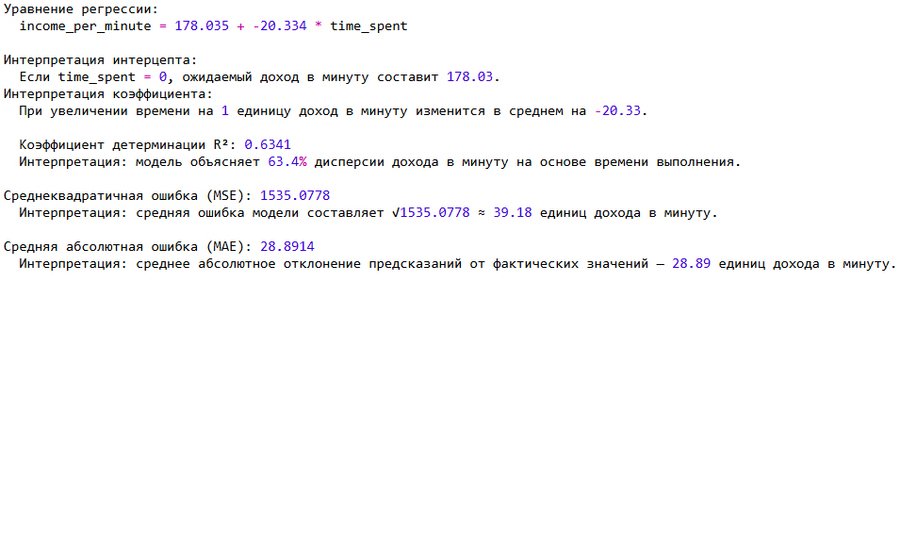
После обучения модель приняла вид: income_per_minute = 178.03 − 20.33 * time_spent
Интерпретация коэффициентов:
β₀ (178.03): если пользователь вообще не тратит время в соцсетях, его доход в минуту составит 178.03
β₁ (—20.33): каждая лишняя единица времени снижает доход в минуту в среднем на 20.33
На диаграмме рассеяния показаны реальные точки и линия регрессии. Наблюдается выраженная отрицательная линейная зависимость.
Качество модели:
R² = 0.634 → модель объясняет 63,4% вариации дохода MSE = 1535.08 → средняя ошибка ≈ 39.18 MAE = 28.89 → среднее абсолютное отклонение модели
Заключение
В рамках проекта я провёл полный цикл анализа пользовательских данных о времени в соцсетях. Заменил пропуски, устранил выбросы, создал новые признаки, применил фильтрацию, сортировку и построил сводные таблицы. Описал числовые и категориальные признаки, визуализировал распределения, посчитал центральные тенденции, меры разброса, квартильные характеристики и корреляции. На очищенных данных обучил парную линейную регрессию, интерпретировал коэффициенты и метрики качества модели. Все шаги оформлены графически в едином стиле — от первичного анализа до финальной модели.
Описание применения генеративной модели
В данном проекте использовались нейросети ChatGPT и DeepSeek для генерации кода и помощи в анализе данных.
Обложка и все иллюстрации были созданы с помощью ChatGPT.
Ссылки



