
Dreamscape
Концепция
Как человек с насыщенными и частыми сновидениями, я задумалась о том, как генерация сновидения в человеческом сознании и генерация изображения с помощью нейросети могут быть похожи по своей сущности. И в том, и в другом случае наблюдается процесс, при котором из обширного объёма информации формируются новые, порой неожиданные комбинации идей и образов. В этом проекте я хотела проверить сможет ли генеративная модель создать насыщенное изображение пространства сна.
Генерации

Для обучения модели были предоставлены 26 изображений, собранные мной на просторах Pinterest. Для генерации изображений была подключена библиотека Hugging Face Hub и подготовлена модель генерации изображений Stable Diffusion XL.









В ходе генераций были получены 15 изображений разной степени проработки. Изображения соответствуют промтам по композиции и атмосфере. Однако интересно отметить, что большей части изображений используется розовый цвет различной насыщенности, хотя изображения для обучения в большинстве своем в сине-зеленых оттенках. В промтах не были указаны цвета, но были указаны другие параметры, влияющие на цветовую составляющую картинки. Например: light, glowing neon lights, vibrant yet dark, vibrant abstract colors, soft transitions, dreamlike glow, trippy color scheme.
Да, абстрактные фантастические изображения были сгенерированы. Однако, на мой взгляд они далеки от выразительных референсов, на которых генеративная модель обучалась.






Сны основываются на наших эмоциях, убеждениях и опыте, тогда как результаты работы искусственного интеллекта зависят от данных, на которых он был обучен. Сновидения — продукт сложных биологических и нейронных процессов, тогда как генеративный ИИ представляет собой искусственную систему, основанную на алгоритмах и статистических моделях. Недостаточно обученная генеративная модель как человек со скупым воображением: результат их деятельности зачастую блеклый и невыразительный. Конечно, можно «накормить» нейросеть множеством изображений, чтоб она нарисовала нужную картинку. Это легко и бездумно. Однако, лучше вложиться в другую генеративноую модель — собственный мозг и воображение, насыщать их информацией и поощерять развитие.
Принцип работы кода
Организация работы начинается с установки необходимых библиотек и загрузки фотографий, на основе которых будет обучаться нейросеть.

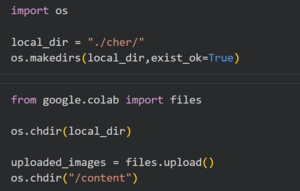
Проводится проверка загрузки фотографий: выводим несколько случайных для проверки.
Далее загружаем модель BLIP и создаём функцию для описания изображения текстом и подготавливаем изображения для обучения модели.
Устанавливаем Hugging Face, с помощью которого и будет проводиться обучение модели. Задаем параметры обучения: общее количество шагов обучения 500, каждые 250 шагов результат сохраняется, также были выставлены настройки, снижающие нагрузку на видеопамять. Сохраняем модель для дальнейшей генерации изображений.
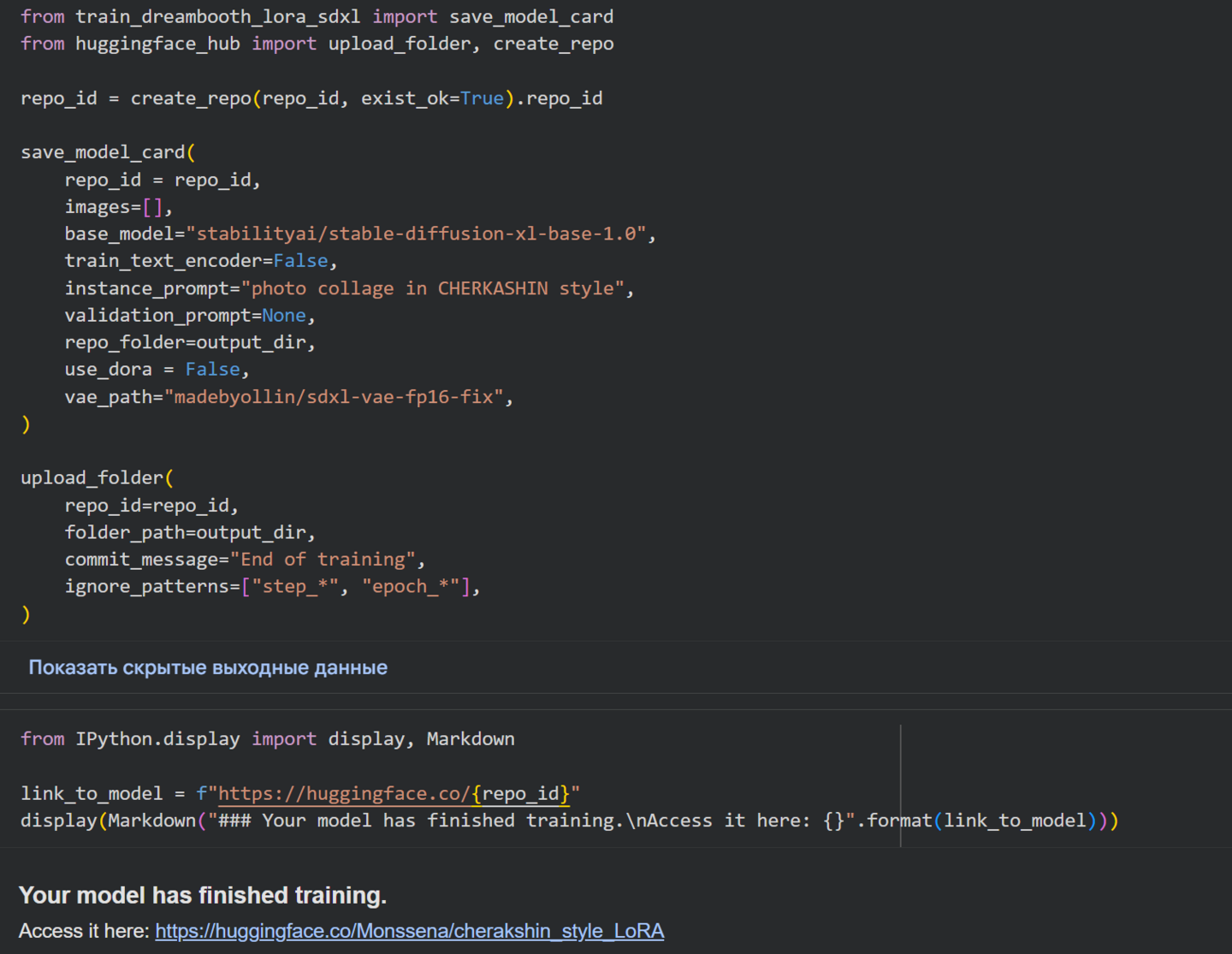
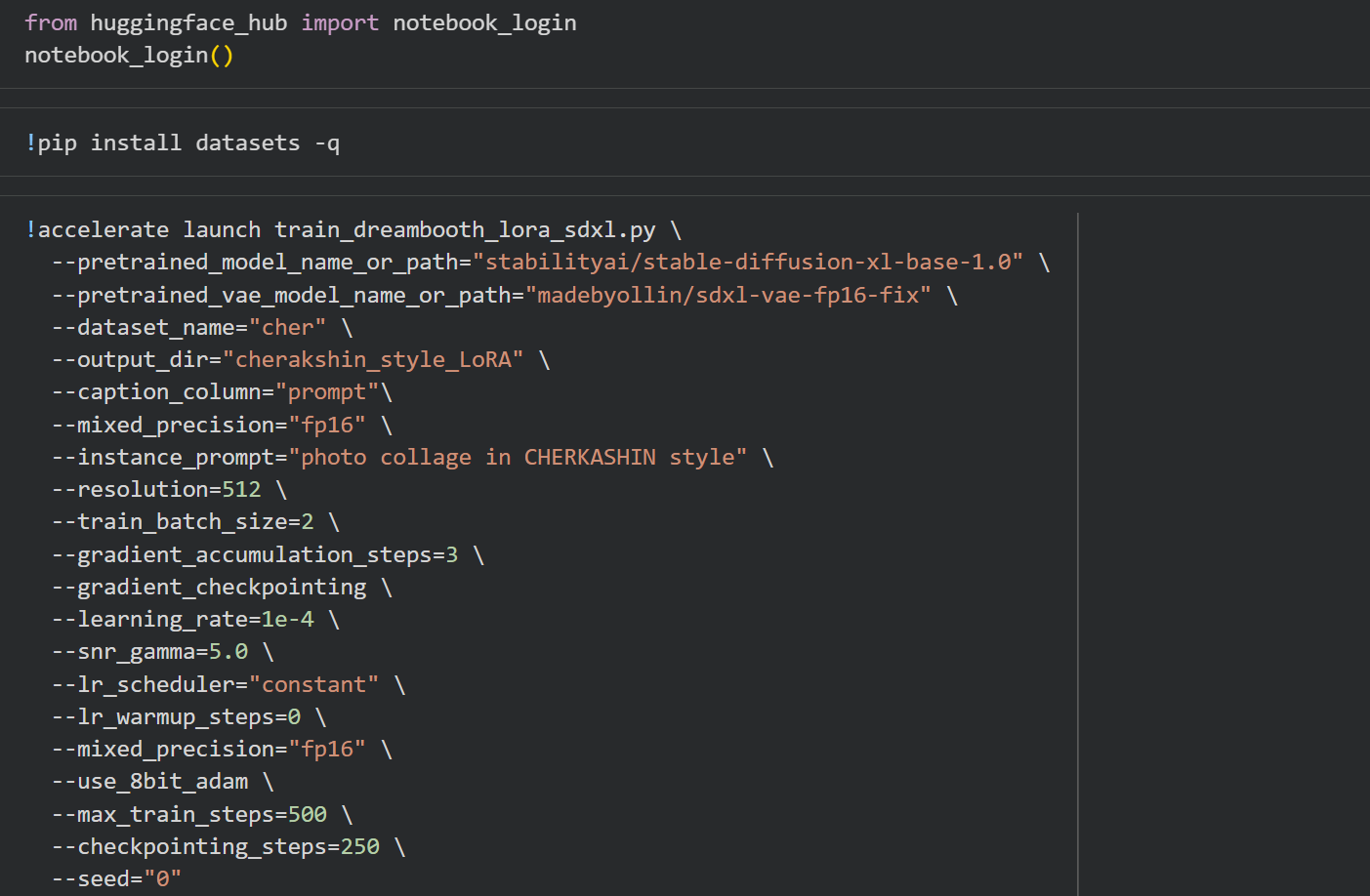
Подготавливаем модель генерации изображений Stable Diffusion XL с использованием обученной модели библиотеки Hugging Face и генерируем изображение.
")
")

")